Paper Reading | EuroSys '20 | Borg: the Next Generation
Borg 是 Google 内部使用的集群资源管理系统,也是 Kubernetes 的前身,因此可以在 Kubernetes 的架构中看见不少 Borg 的影子1,有关 Borg 本身架构的介绍可以参见 Google 于 EuroSys 2015 上发表的论文2。Google 在 2020 年 04 月发布了有关 Borg 集群管理系统的最新跟踪数据3,这是自 2011 年以来发布的最新数据,包括 Machine events、Collection events、Instance events 与 Instance usage 四个维度的数据,总计 2.8 TiB。Google 同时也在 EuroSys 2020 上发表了对其进行分析的论文4,该文将 2019 年的数据与 2011 年的数据进行了全方面的对比,包括资源利用率与资源消耗等,同时指出了两者都存在的重尾效应,并在文末给出了一些可能的研究方向。本文主要基于上述论文进行介绍,并基于文末所提出的可能的研究方向进行一些简单的讨论。
Borg
基本概念
- 集群与单元
- 集群(cluster)
- 一个 Google 集群由一组机器组成,这些机器被放置在物理机价上,并且由高带宽的集群网络连接
- 单元(cell)
- 一个单元由一组机器组成,通常都在一个集群之中,这些机器共享一个集群管理系统
- 集群(cluster)
- 作业与任务
- 作业(job)
- 一个作业由一个或多个任务组成,其描述用户想运行的计算
- 任务(task)
- 一个任务代表一个将会在单个机器上运行的 Linux 程序,可能由多个进程组成
- alloc
- 一个 alloc set 由一个或多个 alloc(实例)组成,其描述作业可以在其中运行的资源保留
- 一个作业可以指定一个 alloc set,该作业会在其中运行,在这种情况下,它的每个任务将在该 alloc set 的一个alloc instance 中运行
- 如果一个作业没有指定 alloc set,那么它的任务将直接使用机器的资源
- 作业(job)
- 集合与实例
- 集合(collection)
- 作业与 alloc set 的总称
- 实例(instance)
- 任务与 alloc 的总称
- 事物(thing)
- 指代集合或实例
- 集合(collection)
作业的优先级
优先级的概念被广泛应用在基于优先级的抢占式调度当中,其表达的是任务之间的相对重要性,在资源不足的情况之下高优先级的任务会对低优先级的作业进行抢占,低优先级的作业便会遭到驱逐并释放它的资源。一般而言,作业会被分成两个种类:批处理作业与服务型作业,后者的优先级会比前者要高,而负责保证基础设施可用性的监控应用通常会具有最高的优先级。下表为 Borg 基于不同阶层(tier)定义的优先级:
| Tier | Priority (2011) | Priority (2019) | Description |
|---|---|---|---|
| Free tier | 0 与 1 | <= 99 | 优先级最低且无内部收费的作业,无 SLO |
| Best-effort Batch (beb) tier | 2-8 | 100-1155 | 批调度器管理且低内部收费的作业,无 SLO |
| Mid-tier | 无 | 116-119 | 提供比生产阶层更低的 SLO 且低内部收费的作业 |
| Production tier | 9-10 | 120-359 | 需要高可用且内部全额收费的作业,Borg 会为了保证生产阶层的作业的服务质量驱逐低阶层的作业 |
| Monitoring tier | 11 | >= 360 | 对于基础设施而言重要的作业,包括监控 |
跟踪数据的对比
2011 年的跟踪数据包含 40 GiB 的压缩数据,即 2.8 TiB 的完整数据;而2019 年的跟踪数据包含平均每个集群 350 GiB 的压缩数据。下表概括了 2011 年与 2019 年跟踪数据的变化:
| 日期 | 2011-05 | 2019-05 |
|---|---|---|
| 持续时间 | 30 天 | 31 天 |
| 集群 | 1 | 8 |
| 机器 | 12.6k | 96.4k |
| 每个集群的机器 | 12.6k | 12.0k |
| 硬件平台 | 3 | 7 |
| 作业优先级的值 | 将唯一值映射到 0-11 的区间 | 0-450,详情见上节 |
| CPU 利用率直方图 | 10 | 21 |
| 归一化的 CPU 单位 | 物理 CPU 核数 | 使用抽象的 Google Compute Unit(GCU),1 GCU 在任意机器上都提供相同的算力。该数据根据跟踪数据中的最大机器大小重新调整规模进行归一化,从而得到 Normalized Compute Unit (NCU),其值域为 0 到 1 |
| Alloc sets | 将 alloc set 与其中的作业作为普通作业对待 | 提供作业与 alloc set 的信息,以及任务是如何被映射到 alloc instance 的 |
| 作业依赖 | - | 提供作业依赖数据,能够进行更加精确的错误分析 |
| 批队列 | - | Borg 现在支持多调度器,包括聚合批作业工作负载的批调度器 |
| 垂直扩缩 | - | Autopilot6 |
| 格式 | csv 文件 | BigQuery 表格 |
跟踪数据的结果以时间序列的集合与互补累计分布函数(Complementary Cumulative Distribution Functions,CDF)的形式呈现,以直观地总结数据的分布情况。下文将会从不同的维度针对 2011 年与 2019 年获得的跟踪数据进行比较,包括集群资源利用率与资源消耗。
资源利用率
平均资源利用率(utilization)
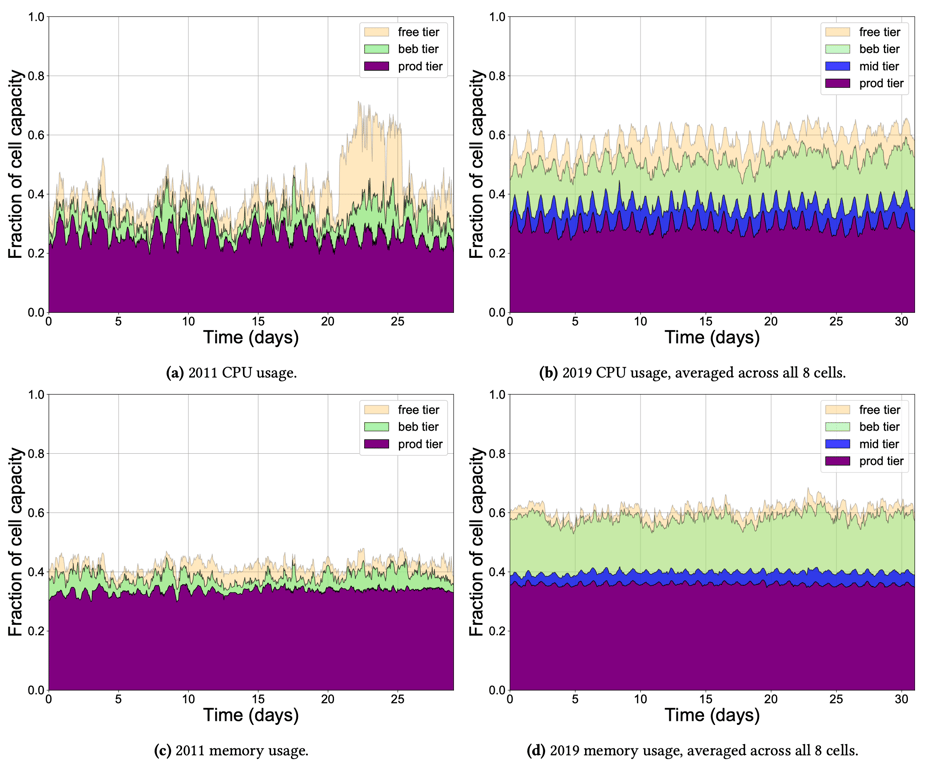
上图是在 2011 年与 2019 年的的跟踪数据的每小时的平均计算与内存资源使用率,这八年间,集群的平均资源利用率有了显著增长,这主要来源于 best-effort batch 阶层,即由批调度器管理的作业,这些作业占据了集群将近 20% 的容量,包括 CPU 和内存。
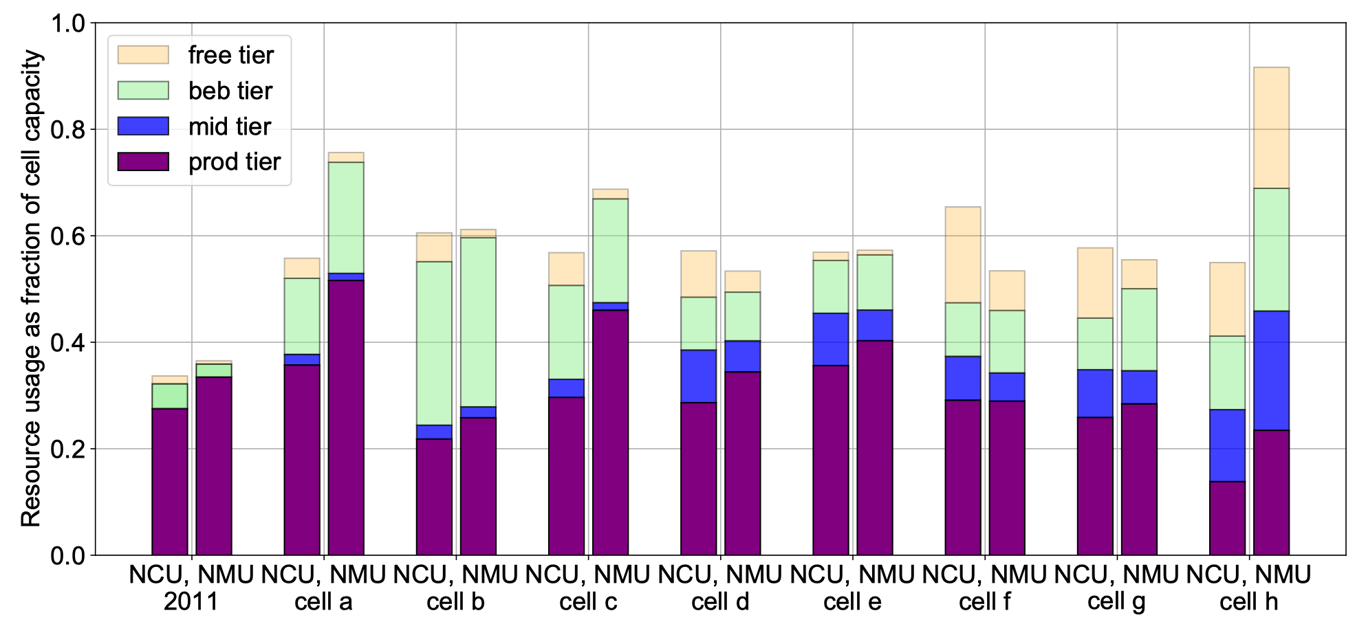
上图展示了不同节点在不同阶层的 CPU 与内存的使用情况,集群之间的工作负载有着相当大的差异,同时在一个集群内部不同的资源维度也存在着差异。
平均资源分配率(allocation)
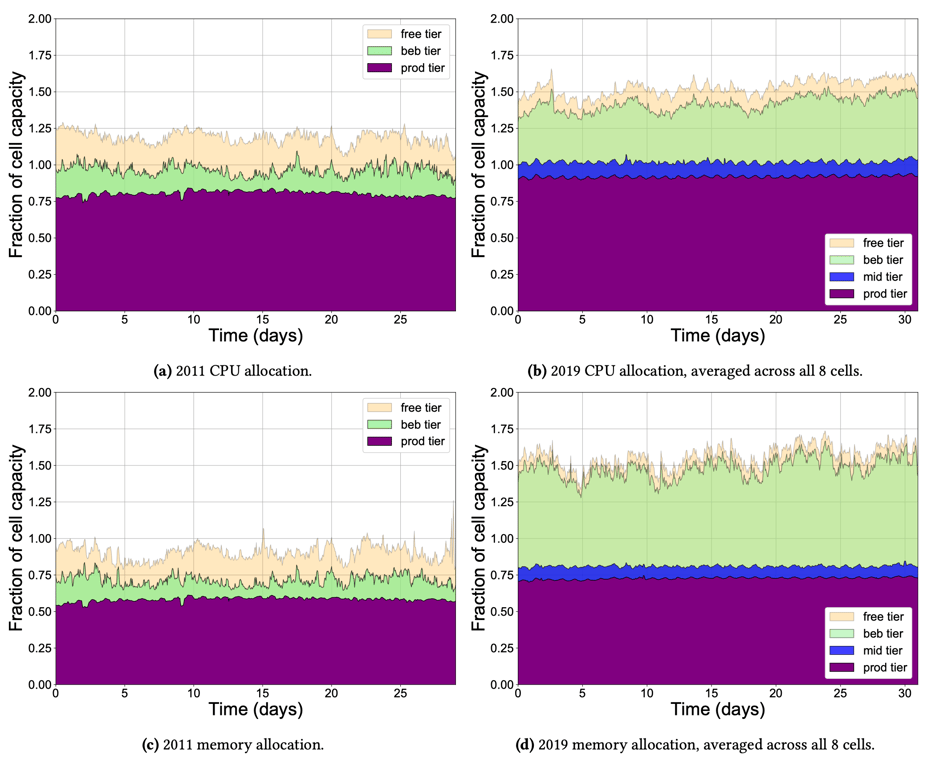
作业通常会指定上限作为其所需的资源上限,从 2011 年至 2019 年,上限的总和显著地增加,CPU 和内存都被分配到远高于 100% 的容量,这表明 Borg 在使用统计多路复用对资源进行超售,即打赌作业会使用比其请求要少的资源。在 2011 年,CPU 比内存更激进地被超售,因为短时间超售 CPU 只会导致 CPU 节流,然后内存不足的话会导致 OOM;而在 2019 年,内存超售的程度已经和 CPU 相当了。
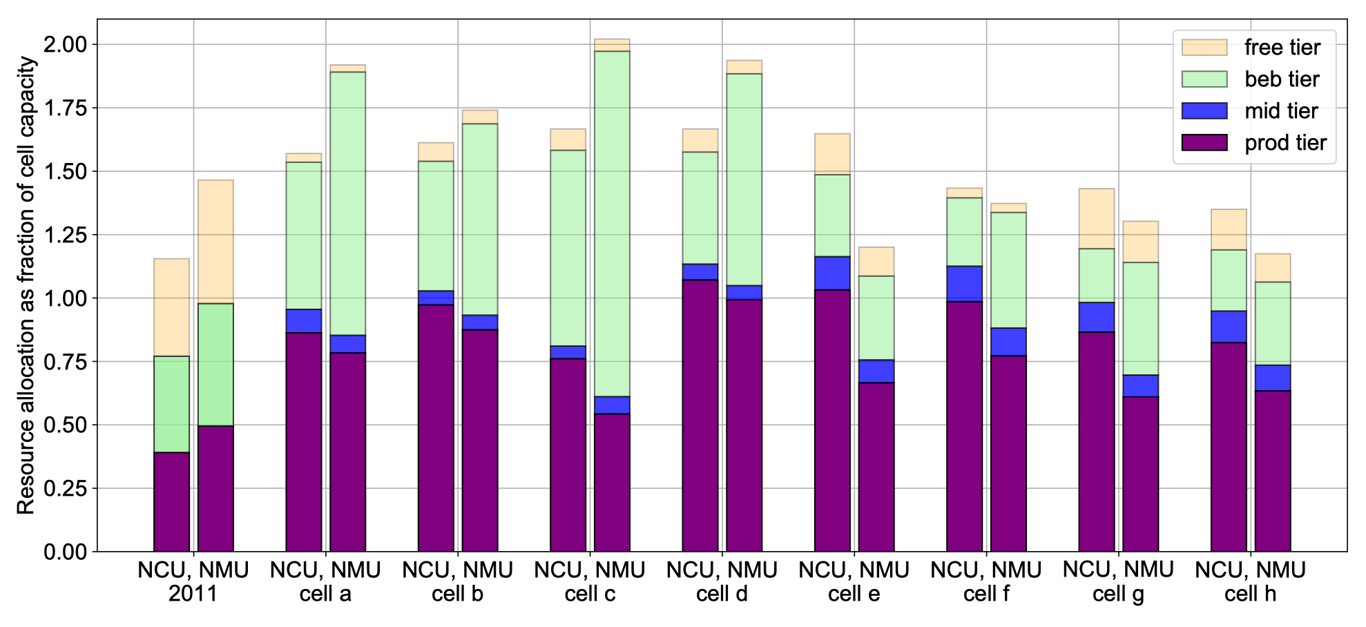
上图展示了不同节点在不同阶层的 CPU 与内存的分配情况,可以看到集群间存在相当大的差异,以及一些高度超售的集群。
机器资源利用率
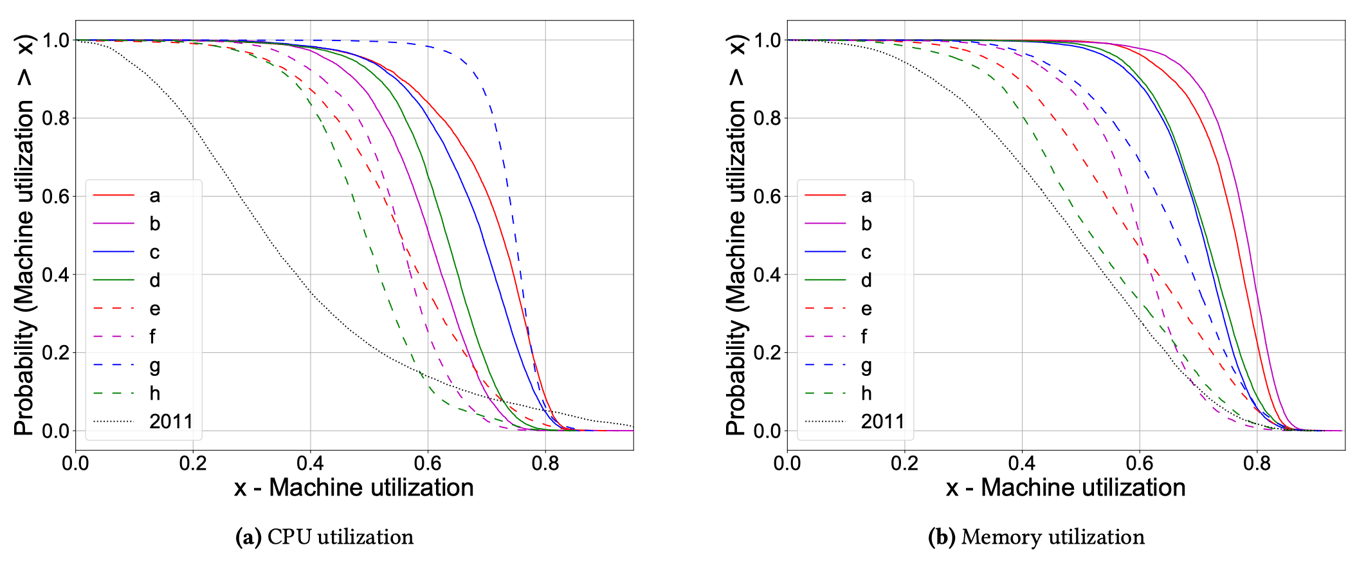
- 与 2011 年的数据相比,2019 年的机器资源利用率更高,最高的百分比除外,对于整体利用率的中位数,CPU 增加了 20-40%,而内存增加了 3-30%;
- 与 2011 年的数据相比,2019 年的机器资源利用率变异性较小;
- 与 2011 年的数据相比,2019 年 CPU 利用率大于 80% 的机器较少。
综合而言,这意味着 Borg 调度器在 2019 年比 2011 年做得更好,其在整个集群中分配工作负载,避免了机器利用率过低和过高。此外,各个集群 CPU 与内存的利用率都存在较大差异,具有异构性;同时 Borg 的工作负载在昼夜周期也存在差异。
调度负载的演变
作业提交速率
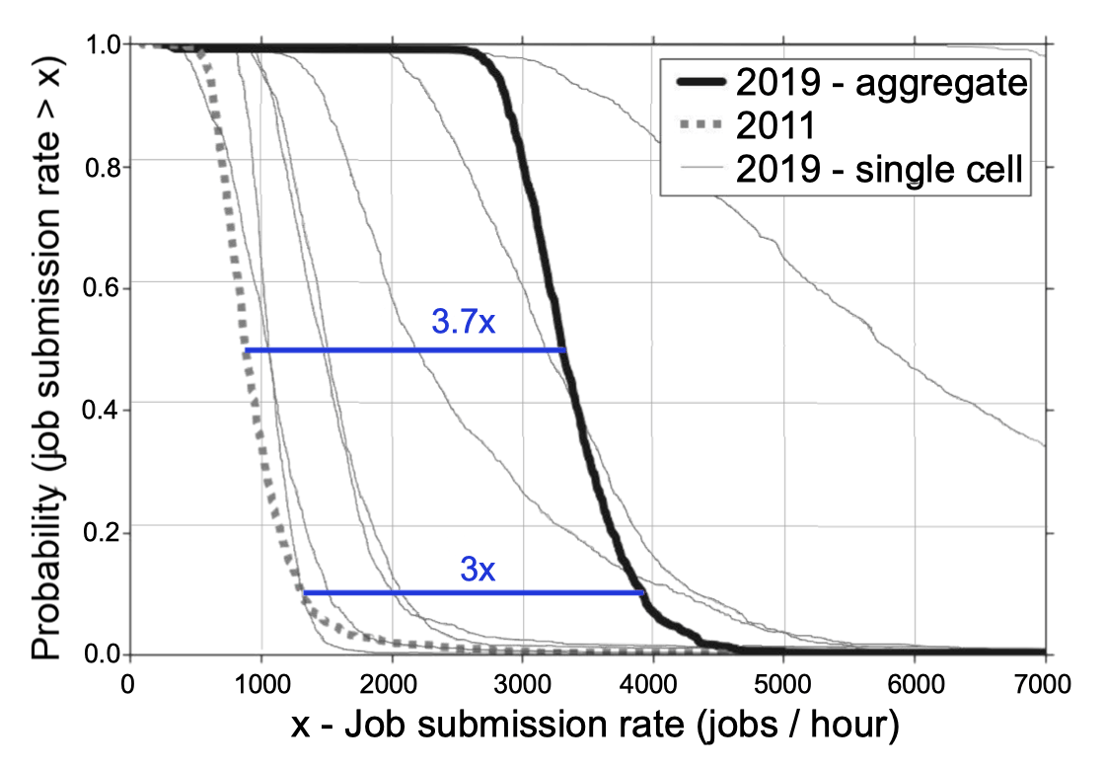
上图为每个集群每个小时给 Borg 调度器提交**作业(Job)**的平均速率的 CCDF。虽然 2011 年与 2019 年的集群规模相当,但是平均作业到达速率从 2011 年的 3360 个作业每小时增长到 2019 年的 3360 个作业每小时(3.5 倍);而到达速率中位数由 885 增长到 3309 个作业每小时(3.7 倍);而 90% 分位点增长了约三倍。
任务提交速率
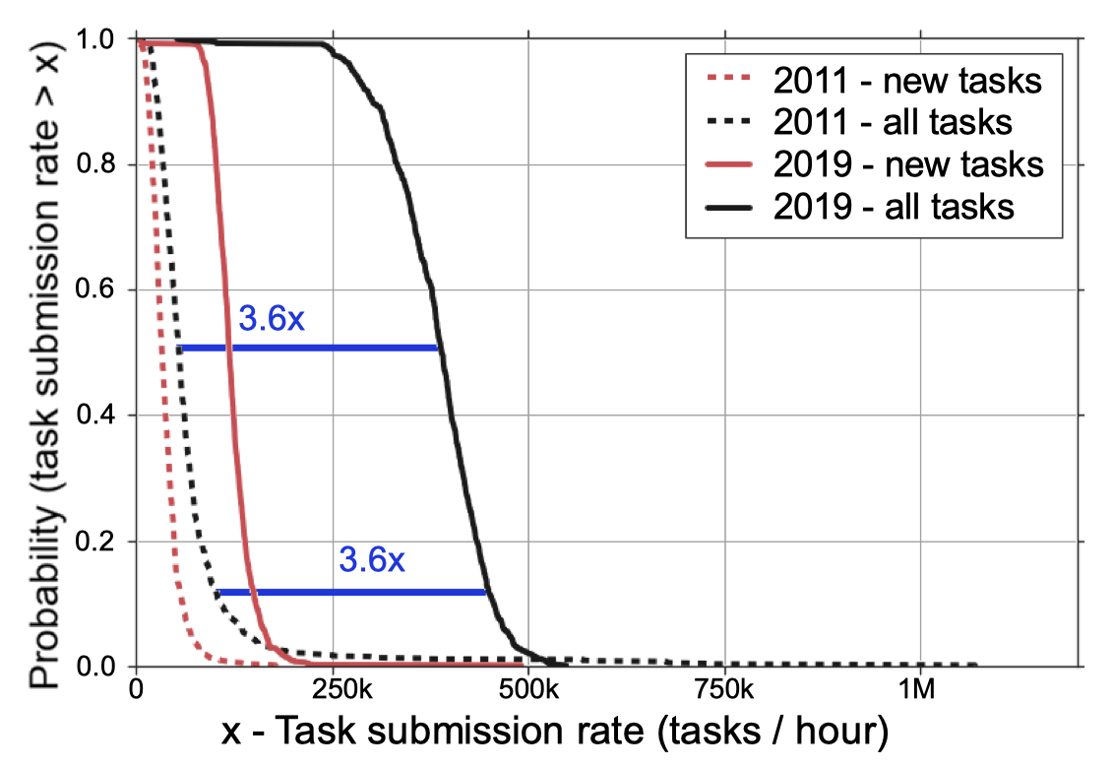
上图为每个集群每个小时给 Borg 调度器提交**任务(Task)**的平均速率的 CCDF,包括新的任务与所有任务,后者包括重调度后的任务。任务调度速率中位数相比 2011 年增长了 3.6 倍。另一方面,很多调度事件是为了重调度,重提交任务率中位数与新任务率中位数之比由 0.66:1 增加到 2.26:1。
调度延迟
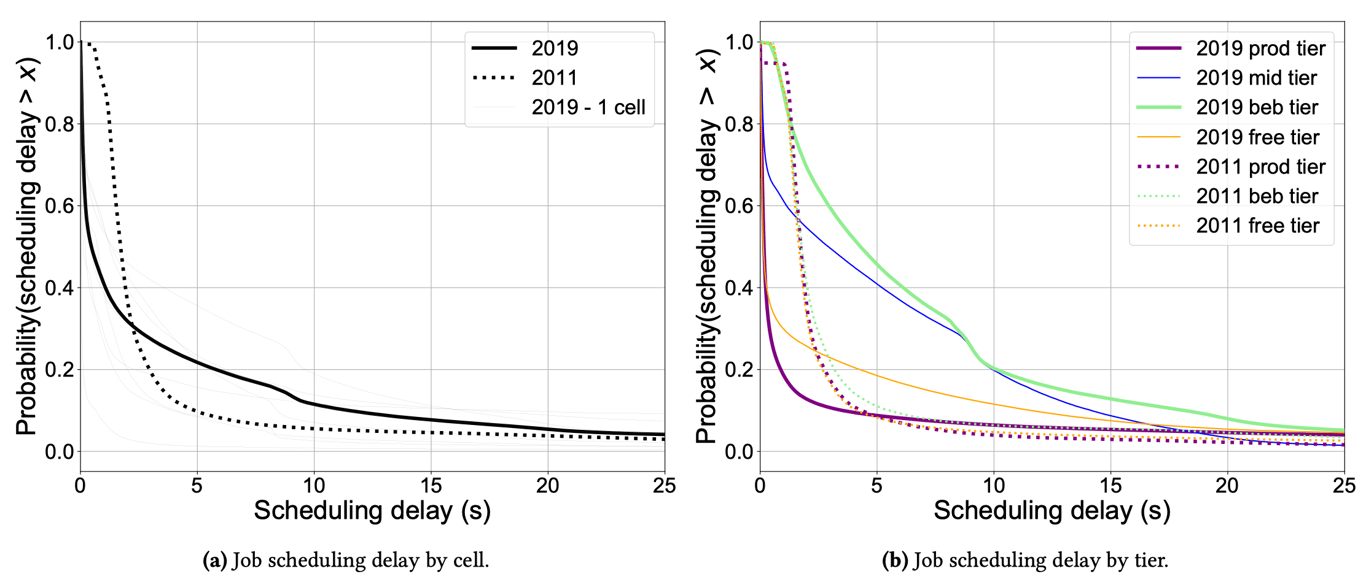
考虑到作业和任务提交率的增加,Borg 调度器可能需要更长的时间来做出调度决定,和/或任务或作业可能保持停滞以等待调度决定,因此作者测量了 Borg 将 Ready 的作业的第一个任务调度到机器上的时间(Running),由此来排除批处理调度器造成的排队延迟。由上图可以发现调度延迟的中位数实际上已经下降,虽然最后 28% 的作业的尾部更长。大部分的长延迟都与 best-effort batch 和 mid 阶层的作业有关,而生产作业的调度明显比 2011 年快。
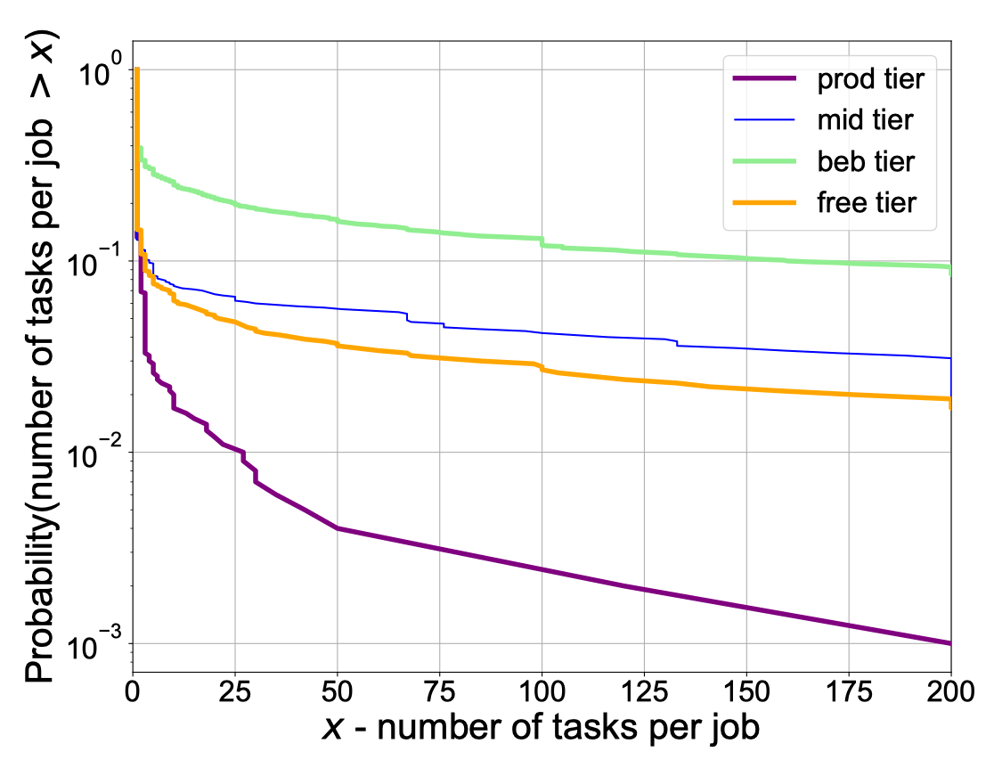
为了理解上述现象的原因,作者根据阶层查看了每个作业的任务数量,从而得知 best-effort batch 和 mid 的任务数比其它层级的要多,因此两者的作业需要更多时间进行调度。
资源消耗
| Measure | 2011 (NCU-hours) | 2019 (NCU-hours) | 2011 (NMU-hours) | 2019 (NMU-hours) |
|---|---|---|---|---|
| median | 0.15e-3 | 0.05e-3 | 0.07e-3 | 0.03e-3 |
| mean | 3.00 | 1.19 | 3.00 | 0.67 |
| variance | 75.2k | 33.3k | 99.0k | 19.8k |
| 90%ile | 0.03 | 0.005 | 0.01 | 0.004 |
| 99%ile | 10.5 | 1.33 | 5.2 | 0.65 |
| 99.9%ile | 248 | 69.67 | 196 | 36.6 |
| maximum | 138k | 370k | 151k | 299k |
| top 1% jobs load | 97.3% | 99.2% | 98.6% | 99.1% |
| top 0.1% jobs load | 83.0% | 93.1% | 89.3% | 92.6% |
| 8375 | 23312 | 11001 | 43476 | |
| Pareto() | 0.77 | 0.69 | 0.72 | 0.72 |
| 99.8% | 99.9% | 99.8% | 99.6% |
平方变异系数
作者在这边使用平方变异系数来衡量获得数据的离散程度,由于该值不会因为归一化而受到影响,因此作为衡量的标准相当合适,其定义如下:
对于指数分布,。一份 2017 年的针对缓存在 Akamai 的十亿个对象的大小的研究表明,针对香港的跟踪数据有 ,针对美国的跟踪数据有,具有“极高的变异性”。而 2019 年的工作负载甚至比前者还要再多一到两个数量级,在计算消耗方面,平均值仅为 1.2 NCU 小时,反差约为 33.3k,因此 ;在内存方面,数据更加极端,平均值为 0.67 NMU 小时,反差约为 19.8k,因此 ,两者的平方变异系数都很高。
帕累托分布
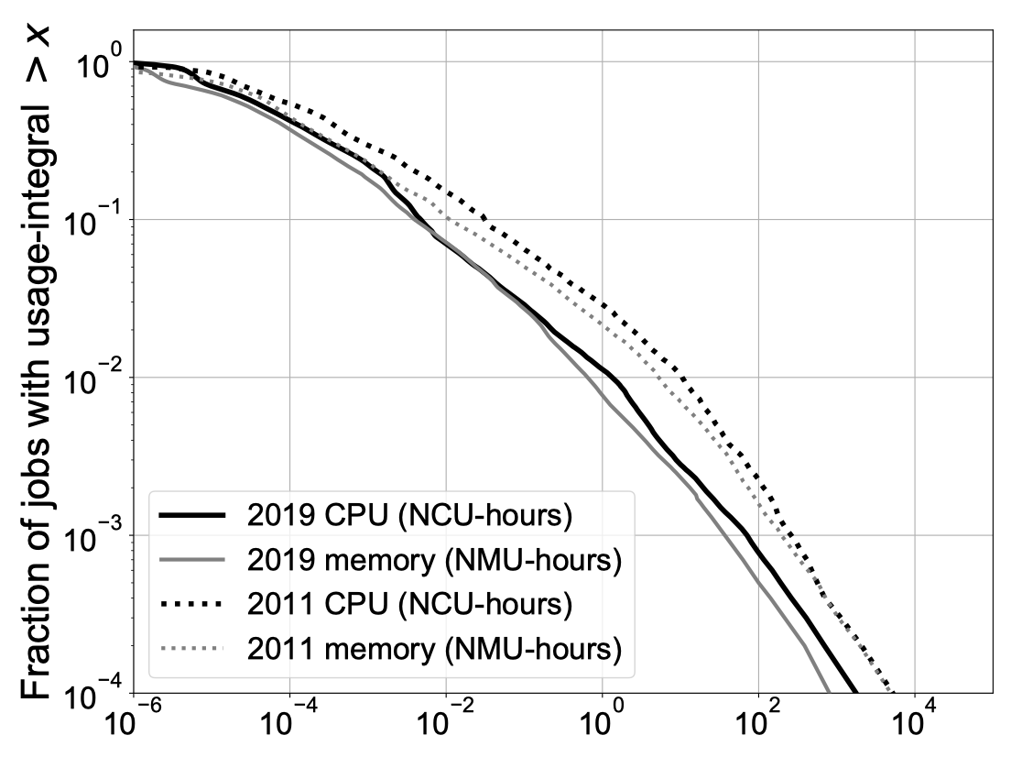
另一方面,上图为 2011 年与 2019年的跟踪数据中的作业的资源使用小时的 log-log 维度的 CCDF,由图像可知两者满足幂定律,具体而言,两者服从帕累托分布:
其中 为负斜率(NMU-hours 同)。可以将 2019 年的数据以 (CPU)与 (内存)拟合为帕累托分布,并且决定系数 皆大于 99%。
帕累托分布是以经济学家维尔弗雷多·帕累托命名的,是从大量真实世界的现象中发现的幂分布定律。对于帕累托分布,尤其是 的情况下,代表该分布具有重尾的特性,即少数的最大的作业占据了大部分负载,这比通常所说的“二八”定律(即前两成大的作业占据了八成的工作负载)还要极端。在先前的研究中作者们观察到了重尾属性,即前 1% 的最大作业占了 50% 的负载,而在 2019 年的追踪数据中分布更加极端:前 1% 的最大作业占了 99.2% 的 CPU 负载,99.1% 的内存负载;前 0.1% 的最大作业占了 93.1% 的 CPU 负载,92.6% 的内存负载。
与 2011 年的数据的对比
在 2011 年的数据中也有类似的情况,尽管没有那么极端,虽然就规模而言 2011 年的数据只有 2019 年数据的八分之一,且原始机器的规模也不同,但是可以基于平方变异系数与整体分布参数进行比较,两者在归一化后都是不变的。虽然 2011 年的数据差异程度没有那么大(是 2019 年的四分之一),其依然服从帕累托分布,且重尾现象相对不严重,但和其它研究相比依旧很高。
计算与内存资源消耗的关系
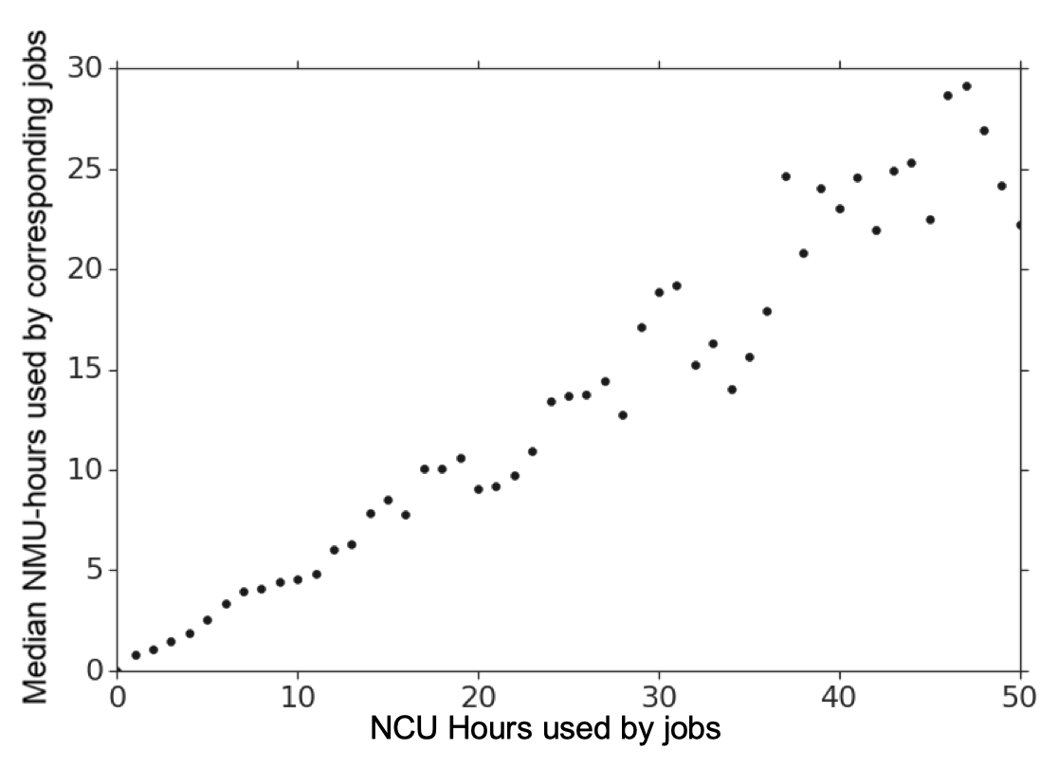
从上一节当中的图像可以发现,计算和内存的消耗几乎服从于相同的分布,因此考虑两者的相关性是十分合理的。上图的横坐标是 NCU 小时,纵坐标为相对应的 NMU 小时的中位数,可以发现拟合出来的几乎是一条直线(Pearson 相关系数为 0.97),实际上考虑到作业运行的时长是两者的共同因素,这个结果并不是那么令人惊讶。
计算和内存消耗对排队延迟和调度的影响
基于排队论,根据 Pollaczek-Khinchin 公式,对于 M/G/1 队列有:
其中 是负载, 是作业大小的平方变异系数。
我们可以发现即使在负载较低的时候,如果 较大就意味着排队延迟的期望依旧会很高,同时作业大小的分布会很广,可以想见一定有小型的作业被堵塞在大型的作业之后,而大规模数据中心的调度肯定会比 M/G/1 队列要复杂得多。因此在这样的情况之下,我们必须找到一种方法来进行调度,使得这些小型任务优先于大型任务,或者以某种其它方式与它们隔离。
如果调度器能确保仅仅 1% 的(大型)作业不妨碍其它 99% 的(小型)作业,那么后者就可以在几乎不排队的情况下运行,同时会运行得更加快速。在上一节中也提到了计算和资源具有较强的相关性,因此这边的解决方案更倾向于排除大型任务本身,而不是分别基于 CPU 或内存进行资源隔离。
垂直扩缩
详情请见 Autopilot: workload autoscaling at Google4。
讨论
作者在文末进行了在生成跟踪数据时的经验总结与针对未来可能的研究方向的展望。
- 可解释的调度
- 调度器是高度复杂的实体,必须考虑到集群状态和工作负载的快速变化。如果能够为调度器做出的决定提供解释就更好了——无论是帮助系统帮助人员理解正在发生,或是即将发生的事情,还是为终端用户提供指导,告诉他们如何更好地使用集群。
- Google 在 2015 年发表的有关 Borg 的论文中提到,Borg 的调度流程主要分为两部分:可行性检查(feasibility checking)与打分(scoring),这与目前 Kubernetes 中的设计是一致的,包括抢占式调度的部分,因此我认为在这部分可解释性还是相当充分的。然而在更为复杂与重量级的调度场景之下,现有的调度策略可能无法满足延迟或者吞吐量的需求,尤其是对外提供服务的系统一般会定义相应的 SLO,因此会根据需要引入更加复杂的调度策略,包括分时调度或动态调度等,甚至在大多数情况下是各种不同的调度策略是在同时作用的,这对调度的可解释性而言也是个很大的挑战。
- 超售可以被推进到多远?
- 批调度
- 在 Borg 中,只要作业中的任何一个任务开始运行,该作业就会启动,虽然用户可以要求等待更多的任务运行,但是很少有人这么做,而它的算法通常是相对简单的贪婪启发式算法。
- 实际上社区中已经有不少项目提出了
PodGroup的概念,包括 kubernetes-sigs/scheduler-plugins 中的 coscheduling plugin8 与 Volcano9,两者都是源自 kubernetes-sigs/kube-batch。本质上我认为是给有依赖关系的批处理任务(如 Flink 的 JobManger 与 TaskManager,TensorFlow 的 Parameter Server 与 Worker 等),能够进行批量调度的抽象,以保证 all-or-nothing,从而使有限资源不会被占用而未使用,同时也能够基于作业的特性对其分布进行约束减小网络的开销。
- 为什么平均资源利用率相对较低?
- 尽管做了大量的努力,计算和内存资源的平均利用率仍然较低。一种假设是,这与故障恢复协议有关,其中三分之一的外部负载(在 2+1 冗余系统中)几乎可以瞬间切换到一个目标单元;另一种假设是存在时间和/或每台机器的变化,其阻止了更紧密的装箱。
- 在提高集群资源利用率的同时保证应用的稳定性是相当具有挑战性的,因此存在一定的冗余是必要的,当然这与数据中心的容灾设计有关。另一方面,针对实时性的调度,我认为关键在于其获取的集群状态的实时性,基于有效的数据调度器才能做出符合当前集群状态的判断,这可能和基础设施本身的成熟度有关。
- 针对重尾的调度
- 前 1% 计算密集型的作业占据了 99% 的 CPU 使用,如何进行调度使剩下 99% 的作业与这些 1% 的作业部分或完全隔离,从而使他们在一个轻量的负载环境中运行会是个有趣的研究。
- 为了有效地提高集群资源的利用率,混合部署是当前的大势所趋,但是在混合部署的情况下资源的隔离是相当有必要的,在此基础上也可以进行更加细粒度的分析,将不同类型的工作负载进行隔离,形成工作负载感知的调度,也可以引入安全容器来提高其性能隔离,如 gVisor 与 Kata Container 等,当然这会引入一定的开销,因此如何进行 trade-off 也是个有意思的部分。
- 跨节点的差异
- 该分析仅仅触及了新的跟踪数据的八个集群的差异的表面。
- 实际上不同集群的工作负载应该会受到不同维度因素的影响,可能包括部署的区域、工作负载的差异、节点之间的网络传输与作业的依赖等。我认为本文主要还是从比较宏观的层面对数据进行了分析,而缺乏细粒度的横向比较,当然这也仅仅是侧重点的不同,宏观层面的比较也是相当有价值的。
Google 集群使用跟踪数据 v3
本文最后来简单地对本次 Google 所发布的跟踪数据进行概览。
Schema
- Machines
- Machine events
- Collections and instances
- Collection events
- Instance events
- Resource usage
- Instance usage
访问跟踪数据
$ gsutil cp gs://clusterdata_2019_a/instance_usage-*.json.gz <destination dir>$ gunzip instance_usage-000000000000.json.gz$ head -1 instance_usage-000000000000.json
{"start_time":"1838400000000","end_time":"1838700000000","collection_id":"330587238433","instance_index":"111","machine_id":"23624491139","alloc_collection_id":"330587160469","alloc_instance_index":"111","collection_type":"0","average_usage":{"cpus":0.008392333984375,"memory":0.0094757080078125},"maximum_usage":{"cpus":0.04791259765625,"memory":0.019378662109375},"random_sample_usage":{"cpus":0.016632080078125},"assigned_memory":0,"page_cache_memory":0.0032196044921875,"cycles_per_instruction":0.89924430847167969,"memory_accesses_per_instruction":0.00151212012860924,"sample_rate":0.996666669845581,"cpu_usage_distribution":[0.0004711151123046875,0.0006809234619140625,0.00075817108154296875,0.00083160400390625,0.00096225738525390625,0.0084381103515625,0.008880615234375,0.0133056640625,0.016448974609375,0.021942138671875,0.04779052734375],"tail_cpu_usage_distribution":[0.022308349609375,0.023681640625,0.024200439453125,0.025360107421875,0.02606201171875,0.02685546875,0.028411865234375,0.030853271484375,0.0369873046875]}结语
这是 Google 时隔五年之后又发表了 Borg 相关的文章,当初看见 conference program 的时候原本以为是偏向系统架构层面的介绍,没想到后面 proceeding 出来了之后才发现是介绍 tracing 的文章。如同上文所讲述的,于 EuroSys 2020 发表的论文主要是介绍本次发布的 2019 年的跟踪数据与 2011 年的数据的对比,实际上涉及到 Borg 本身的架构较少,多数与 2011 年的时间点相比新增的的部分在 EuroSys 20152 与 Autopilot4 中都进行了详细的介绍。
Google 作为全球拥有数一数二规模的集群的公司能够将其跟踪数据发表出来我认为是相当有价值的,不仅为数据量不充足的研究者提供了数据基础,同时也为希望在集群资源管理,包括多维度调度与容量管理进行进一步深入研究的人,通过本文的分析提供了可能的方向。
Footnotes
-
Borg: Kubernetes 的前身. https://kubernetes.io/zh/blog/2015/04/borg-predecessor-to-kubernetes/ ↩
-
Abhishek Verma, Luis Pedrosa, Madhukar Korupolu, David Oppenheimer, Eric Tune, and John Wilkes. 2015. Large-scale cluster management at Google with Borg. In Proceedings of the Tenth European Conference on Computer Systems (EuroSys ‘15). Association for Computing Machinery, New York, NY, USA, Article 18, 1–17. DOI:https://doi.org/10.1145/2741948.2741964 ↩ ↩2
-
John Wilkes. Yet More Google Compute Cluster Trace Data. https://ai.googleblog.com/2020/04/yet-more-google-compute-cluster-trace.html ↩
-
Muhammad Tirmazi, Adam Barker, Nan Deng, Md E. Haque, Zhijing Gene Qin, Steven Hand, Mor Harchol-Balter, and John Wilkes. 2020. Borg: the next generation. In Proceedings of the Fifteenth European Conference on Computer Systems (EuroSys ‘20). Association for Computing Machinery, New York, NY, USA, Article 30, 1–14. DOI:https://doi.org/10.1145/3342195.3387517 ↩ ↩2 ↩3 ↩4
-
John Wilkes. Google cluster-usage traces v3. https://drive.google.com/file/d/10r6cnJ5cJ89fPWCgj7j4LtLBqYN9RiI9/view. 论文中为 110-115,实际为笔误。 ↩
-
Krzysztof Rzadca, Pawel Findeisen, Jacek Swiderski, Przemyslaw Zych, Przemyslaw Broniek, Jarek Kusmierek, Pawel Nowak, Beata Strack, Piotr Witusowski, Steven Hand, and John Wilkes. 2020. Autopilot: workload autoscaling at Google. In Proceedings of the Fifteenth European Conference on Computer Systems (EuroSys ‘20). Association for Computing Machinery, New York, NY, USA, Article 16, 1–16. DOI:https://doi.org/10.1145/3342195.3387524 ↩
-
Noman Bashir, Nan Deng, Krzysztof Rzadca, David Irwin, Sree Kodak, and Rohit Jnagal. 2021. Take it to the limit: peak prediction-driven resource overcommitment in datacenters. Proceedings of the Sixteenth European Conference on Computer Systems. Association for Computing Machinery, New York, NY, USA, 556–573. DOI:https://doi.org/10.1145/3447786.3456259 ↩
-
https://github.com/kubernetes-sigs/scheduler-plugins/blob/release-1.19/pkg/apis/scheduling/v1alpha1/types.go#L116 ↩
-
https://github.com/volcano-sh/apis/blob/release-1.19/pkg/apis/scheduling/v1beta1/types.go#L144 ↩