Getting Started with Apache Kafka on Kubernetes with Strimzi
Kubernetes
#Kubernetes
#Kafka
#Strimzi
背景
最近由于实验室的项目需要使用消息中间件来支撑整个系统的消息中心,后续也有将整体服务之间的交互更改为事件驱动的计划,所以决定使用 Apache Kafka1 作为系统的消息中间件。Apache Kafka 是一个被广泛使用的基于 ZooKeeper 的分布式流处理平台,最初由 LinkedIn 进行开发,其通过定义 Topic 来进行消息的分类。
在本项目中我们的集群资源是基于 Kubernetes2 进行管理的,因此我们也希望能够将 Kafka 部署在 Kubernetes 之上便于整体的管理和控制。 我们在这里采用的解决方案是由 RedHat 开源的 Strimzi3,Strimzi 是 CNCF 的 Sandbox 级项目,其通过定义 Kubernetes Operator 来达到 Kubernetes-native 的 Kafka 集群管理以及相关组件的控制。
预备
使用场景
这里介绍一下我们使用 Kafka 的具体场景,现阶段 Kafka 主要负责的是对事件的触发进行记录,随后对这些事件的消息进行持久化。
gRPC JDBC Sink Connector
service <----> message server ----> Kafka Cluster (Kafka Connect) --------------------> MySQL
|
client <----------------------------------------------------------------------------------Strimzi
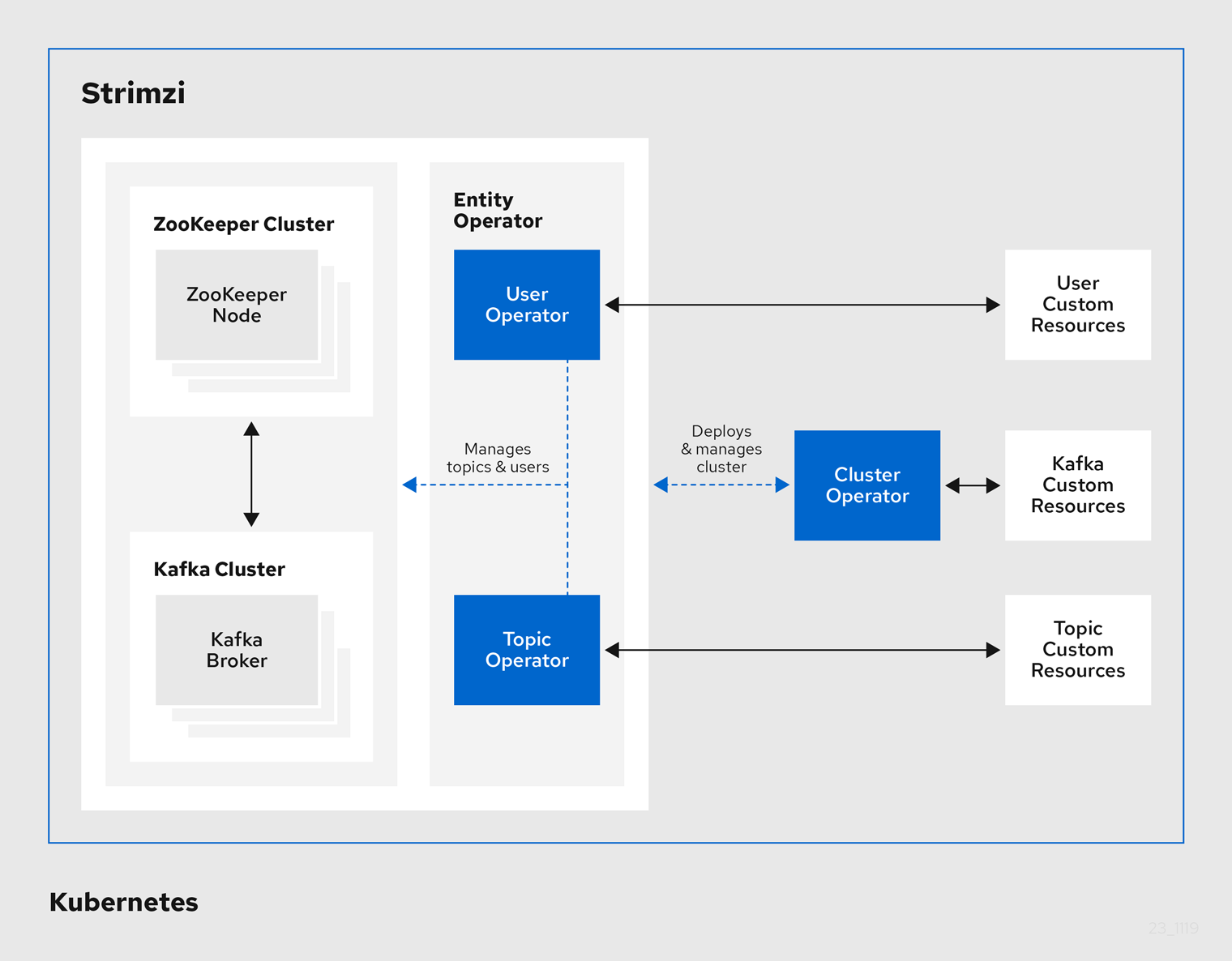
Strimzi 实际上在 repository 里已经给出了许多使用相关 CRD 的例子4,同时也在文档里详细描述了部署的过程5。我们这里主要基于上述的材料进行修改来达到我们实际的使用需求。
Kafka Cluster
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: kafka-cluster
namespace: kafka
spec:
kafka:
version: 2.5.0
replicas: 3
listeners:
plain: {}
tls:
authentication:
type: tls
template:
pod:
securityContext: # strimzi/strimzi-kafka-operator#1720
runAsUser: 0
fsGroup: 0
config:
offsets.topic.replication.factor: 3
transaction.state.log.replication.factor: 3
transaction.state.log.min.isr: 2
log.message.format.version: "2.5"
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 8Gi
deleteClaim: false
class: nfs-storage
zookeeper:
template:
pod:
securityContext:
runAsUser: 0
fsGroup: 0
replicas: 3
storage:
type: persistent-claim
size: 8Gi
deleteClaim: false
class: nfs-storage
entityOperator:
topicOperator: {}
userOperator: {}$ kubectl get all -n kafka
NAME READY STATUS RESTARTS AGE
pod/kafka-cluster-entity-operator-69cdc646f8-4lmsx 3/3 Running 0 42h
pod/kafka-cluster-kafka-0 2/2 Running 0 42h
pod/kafka-cluster-kafka-1 2/2 Running 0 42h
pod/kafka-cluster-kafka-2 2/2 Running 0 42h
pod/kafka-cluster-zookeeper-0 1/1 Running 0 42h
pod/kafka-cluster-zookeeper-1 1/1 Running 0 42h
pod/kafka-cluster-zookeeper-2 1/1 Running 0 42h
pod/strimzi-cluster-operator-7d6cd6bdf7-b54pc 1/1 Running 0 14d
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kafka-cluster-kafka-bootstrap ClusterIP 10.103.3.225 <none> 9091/TCP,9092/TCP,9093/TCP 42h
service/kafka-cluster-kafka-brokers ClusterIP None <none> 9091/TCP,9092/TCP,9093/TCP 42h
service/kafka-cluster-zookeeper-client ClusterIP 10.97.214.15 <none> 2181/TCP 42h
service/kafka-cluster-zookeeper-nodes ClusterIP None <none> 2181/TCP,2888/TCP,3888/TCP 42h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kafka-cluster-entity-operator 1/1 1 1 42h
deployment.apps/strimzi-cluster-operator 1/1 1 1 14d
NAME DESIRED CURRENT READY AGE
replicaset.apps/kafka-cluster-entity-operator-69cdc646f8 1 1 1 42h
replicaset.apps/strimzi-cluster-operator-7d6cd6bdf7 1 1 1 14d
NAME READY AGE
statefulset.apps/kafka-cluster-kafka 3/3 42h
statefulset.apps/kafka-cluster-zookeeper 3/3 42hKafka Connect
FROM strimzi/kafka:0.19.0-kafka-2.5.0
USER root:root
COPY ./third_party/kafka-connect-jdbc-5.5.1.jar /opt/kafka/plugins/
COPY ./third_party/mysql-connector-java-5.1.48.jar /opt/kafka/libs/
USER 1001apiVersion: v1
kind: Secret
metadata:
name: mysql-secret
namespace: kafka
type: Opaque
stringData:
password: PASSWORD
---
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaUser
metadata:
name: kafka-connect-cluster
namespace: kafka
labels:
strimzi.io/cluster: kafka-cluster
spec:
authentication:
type: tls
---
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: kafka-connect-cluster
namespace: kafka
annotations:
strimzi.io/use-connector-resources: "true"
spec:
image: REGISTRY/rudeigerc/custom-kafka
version: 2.5.0
replicas: 1
bootstrapServers: kafka-cluster-kafka-bootstrap.kafka.svc.cluster.local:9092
tls:
trustedCertificates:
- secretName: kafka-cluster-cluster-ca-cert
certificate: ca.crt
authentication:
type: tls
certificateAndKey:
secretName: kafka-connect-cluster
certificate: user.crt
key: user.key
config:
config.providers: file
config.providers.file.class: org.apache.kafka.common.config.provider.FileConfigProvider
group.id: connect-cluster
offset.storage.topic: connect-cluster-offsets
config.storage.topic: connect-cluster-configs
status.storage.topic: connect-cluster-status
key.converter: org.apache.kafka.connect.json.JsonConverter
value.converter: org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable: true
value.converter.schemas.enable: true
externalConfiguration:
volumes:
- name: offset-config
configMap:
name: offset-config
- name: mysql-sink-connector-config
secret:
secretName: mysql-sink-connector-config$ kubectl get pods \
-n kafka \
--selector=app.kubernetes.io/part-of=strimzi-kafka-connect-cluster,app.kubernetes.io/name=kafka-connect \
-o jsonpath='{.items[0].metadata.name}' \
| xargs -o -i kubectl exec {} -it \
-n kafka \
-- /bin/curl kafka-connect-cluster-connect-api.kafka.svc.cluster.local:8083
{"version":"2.5.0","commit":"66563e712b0b9f84","kafka_cluster_id":"4uH6peN4QoKdw7CQGvhxRA"}MySQL Sink Connector
apiVersion: v1
kind: Secret
metadata:
name: mysql-sink-connector-config
namespace: kafka
type: Opaque
stringData:
connector.properties: |-
username: USERNAME
password: PASSWORDapiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaConnector
metadata:
name: mysql-sink-connector
namespace: kafka
labels:
strimzi.io/cluster: kafka-connect-cluster
spec:
class: io.confluent.connect.jdbc.JdbcSinkConnector
tasksMax: 3
config:
topics: test
connection.url: jdbc:mysql://mysql.kafka.svc.cluster.local:3306/demo
connection.user: ${file:/opt/kafka/external-configuration/mysql-sink-connector-config/connector.properties:username}
connection.password: ${file:/opt/kafka/external-configuration/mysql-sink-connector-config/connector.properties:password}
insert.mode: upsert
table.name.format: notification
pk.mode: record_value
pk.fields: id
auto.create: true这里需要注意的是 label 中的 strimzi.io/cluster 指的是 connector cluster 的名称,而不是 Kafka cluster 的名称。
我们在这里采用的是 Confluent 的 JDBC Sink Connector。
参考
- Strimzi - Apache Kafka on Kubernetes
- Using secrets in Kafka Connect configuration
- Introduction to Strimzi: Apache Kafka on Kubernetes (KubeCon Europe 2020)
- Kubernetes-native Apache Kafka with Strimzi, Debezium, and Apache Camel (Kafka Summit 2020)